Call us USA (+1)312-698-3083
| Email : sales@wappnet.com
Machine learning in production is fundamentally different from machine learning in a notebook. A notebook experiment proves that a model can learn from your data. A production ML system proves that the model continues to deliver value over time as data shifts, as business requirements change, and as the engineering team grows.
The gap between these two states is not merely technical; it is a gap in discipline, process, and automation. For organizations investing in AI development services, bridging this gap is critical to ensuring that machine learning models move beyond experimentation and deliver measurable business value in production environments.
MLOps—machine learning operations—is the practice of applying software engineering and DevOps principles to build an end-to-end MLOps pipeline for machine learning workflows. It means versioning data and code together so you can reproduce any training run.
It means automating training and deployment so that retraining is a scheduled job or a triggered pipeline, not a manual ritual. It means testing models before they reach production, monitoring them after deployment, and maintaining a clear audit trail from production predictions back to the code and data that produced the model.
This tutorial walks through one concrete implementation of an end-to-end MLOps pipeline, showing how to build an end-to-end MLOps pipeline from raw data to continuous monitoring: from raw data through training, evaluation, model registration, deployment to a serving API, and ongoing monitoring. The tools are interchangeable—GitHub Actions can be swapped for GitLab CI or Jenkins, MLflow for SageMaker Model Registry, and FastAPI for TensorFlow Serving—but the structure is consistent. The goal is to give you a working reference implementation that you can adapt to your stack and your constraints.

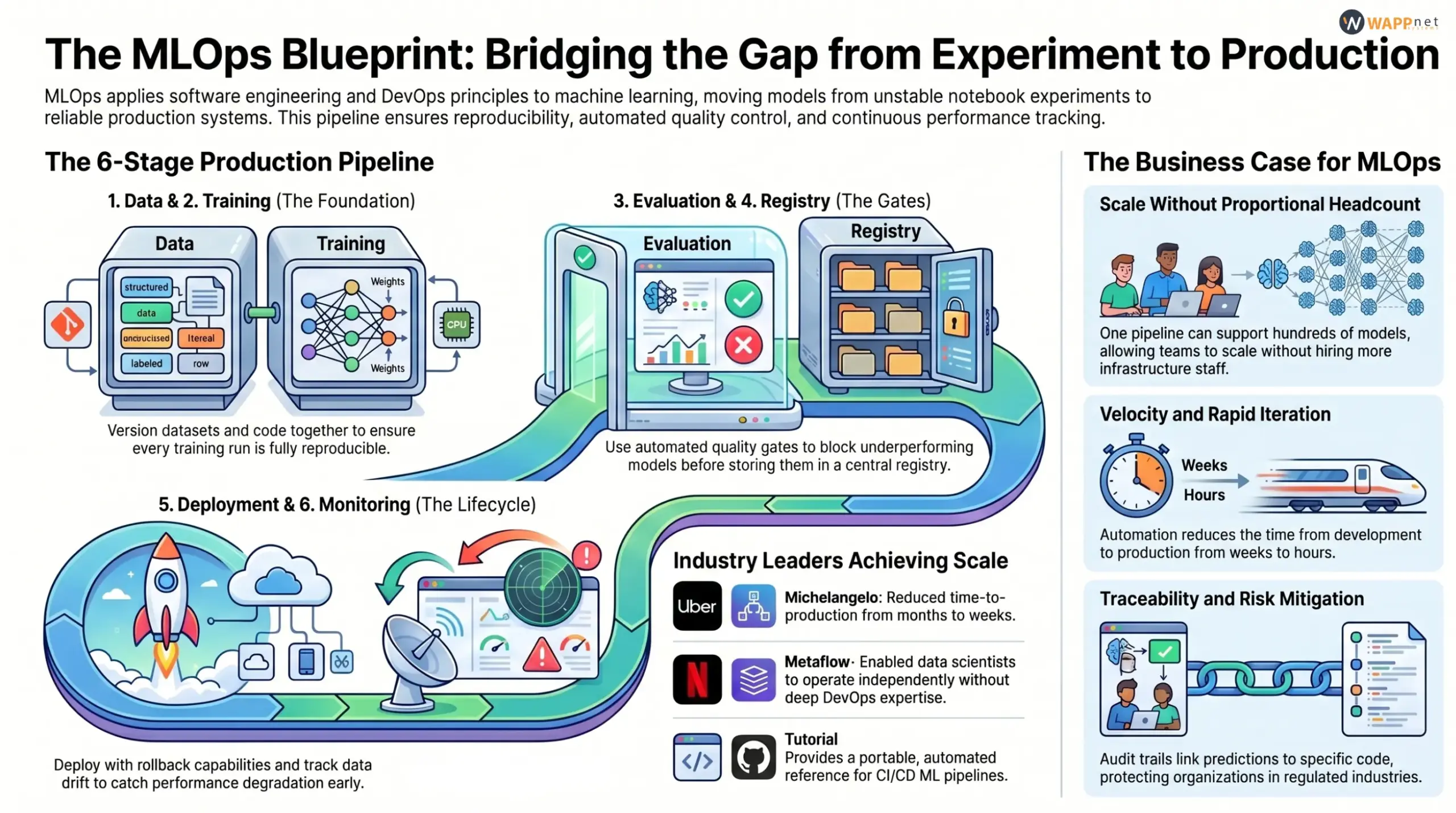
An end-to-end MLOps pipeline covers the complete lifecycle of a model and defines a structured MLOps workflow from ingestion to monitoring. of a machine learning model from initial data ingestion through production deployment and ongoing maintenance. Understanding each stage individually clarifies what is required and where automation adds value.
| 1
Data |
2
Training |
3
Evaluation |
4
Registry |
5
Deployment |
6
Monitoring |
Machine learning models are functions of both code and data. Versioning code without versioning data means you cannot reproduce a training run, which makes debugging and auditing nearly impossible. Data versioning tools like DVC (Data Version Control), Delta Lake, or simple S3 bucket versioning with manifest files allow you to treat datasets as immutable artifacts with version tags.
Data validation ensures that the data fed into training matches expected schemas and quality thresholds. Checks might include column types and ranges, missing value rates, distribution shifts relative to a reference dataset, and uniqueness constraints. Catching data quality issues before training saves time and prevents models trained on corrupted data from reaching production.
Training should be fully automated and reproducible to ensure a reproducible machine learning pipeline across teams and environments. This means the training script accepts explicit inputs—data path or version, hyperparameters, output paths—and produces explicit outputs: a model artifact, training metrics, and metadata linking the run to its code commit and data version. No hardcoded paths, no secrets in code, no manual steps.
Training can be triggered by code changes (via CI/CD), data changes (via a data pipeline), or on a schedule (e.g., weekly retraining). The trigger mechanism is less important than the principle: training is a repeatable process that runs in a known environment and produces traceable outputs.
Not every trained model should reach production. Evaluation gates enforce minimum quality thresholds and, optionally, require that new models outperform the current production model before being promoted. Evaluation might check accuracy, AUC, precision-recall tradeoffs, fairness metrics across demographic slices, or business-specific KPIs.
The evaluation step runs after training and before registration or deployment. If the model fails evaluation, the pipeline stops and does not promote the model. This prevents accidental deployments of undertrained models, models trained on corrupted data, or models that regress on key metrics.
An effective ML model versioning and registry system ensures traceability and governance across environments, and their associated metadata: which code version and data version were used, what metrics the model achieved, who approved it for production, and when it was deployed. The registry provides a single source of truth for which model is currently in production, which models are candidates for promotion, and which models were previously deployed and can be rolled back to if needed.
Simple implementations use object storage (S3, GCS) with a database or JSON file for metadata. Mature implementations use purpose-built tools like MLflow Model Registry, SageMaker Model Registry, or Weights & Biases. The key capability is versioned artifacts with queryable metadata.
Deployment takes a registered model and makes it available to serve predictions, either via a REST API for online inference, a batch job for offline scoring, or an edge deployment for on-device inference. A robust model deployment pipeline ensures version control, rollback capability, and controlled rollout strategies. Deployment should be controlled—ideally with canary or blue-green deployment patterns—and should tag the deployed artifact with its version so that rollback is a matter of redeploying a previous version, not rebuilding from source.
The serving layer must handle model loading, input validation, prediction execution, and error handling. It should also expose health and readiness endpoints for integration with orchestration systems like Kubernetes or ECS.
Once a model is in production, you need continuous visibility into three dimensions: prediction performance (are predictions accurate?), data drift (is the input distribution shifting?), and operational health (is the service responding, and are errors increasing?). Monitoring allows you to detect when a model has degraded and needs retraining, when input data quality has dropped, or when the serving infrastructure is under stress.
Performance monitoring requires capturing predictions and, when ground truth labels arrive, comparing them to compute accuracy over time. Drift monitoring compares feature distributions in production to a reference (training data or recent baseline) and flags significant statistical shifts. Operational monitoring uses standard observability tools: metrics, logs, and traces.
The following walkthrough implements a minimal but complete MLOps pipeline. It assumes a Python-based ML project, GitHub Actions for CI/CD, S3 for artifact storage, and FastAPI for serving. Adapt the specifics to your stack.
Organize the repository so that code, configuration, and pipeline definitions are version-controlled together. Data versioning is handled separately (via DVC or explicit S3 versioning) but referenced in the code.
ml-project/ ├── data/ # or DVC pointer / external storage reference │ └── train.csv ├── src/ │ ├── train.py # training script │ ├── evaluate.py # evaluation and gating │ └── model.py # model definition ├── serving/ │ ├── app.py # FastAPI prediction service │ └── Dockerfile ├── .github/workflows/ │ └── ml-pipeline.yml # CI/CD pipeline definition ├── requirements.txt └── README.md
Every training run is tagged with the git commit SHA so that any model artifact can be traced back to the exact code that produced it. If using DVC for data, the data version is similarly tracked.
The training script accepts all inputs as arguments—data path, output paths for the model and metrics—and produces explicit outputs. This allows the CI/CD pipeline to control where inputs come from and where outputs go.
# src/train.py import argparse, json, os from pathlib import Path def main(): parser = argparse.ArgumentParser() parser.add_argument(‘–data-path’, default=’data/train.csv’) parser.add_argument(‘–model-dir’, default=’outputs/model’) parser.add_argument(‘–metrics-path’, default=’outputs/metrics.json’) args = parser.parse_args() # Load and preprocess data import pandas as pd df = pd.read_csv(args.data_path) # … split, feature engineering … # Train model from src.model import get_model model = get_model() model.fit(X_train, y_train) # Save model artifact Path(args.model_dir).mkdir(parents=True, exist_ok=True) model.save(os.path.join(args.model_dir, ‘model.joblib’)) # Log metrics for evaluation metrics = {‘accuracy’: float(accuracy), ‘auc’: float(auc)} with open(args.metrics_path, ‘w’) as f: json.dump(metrics, f, indent=2) if __name__ == ‘__main__’: main()
Read More: Predictive Incident Management Using AI: From When It Breaks to Before It Breaks
The evaluation script reads the metrics produced by training and enforces quality thresholds. If the model fails to meet the minimum bar, the script exits with a non-zero status, which causes the pipeline to halt and prevents deployment.
# src/evaluate.py import argparse, json def main(): parser = argparse.ArgumentParser() parser.add_argument(‘–metrics-path’, default=’outputs/metrics.json’) parser.add_argument(‘–threshold-accuracy’, type=float, default=0.75) args = parser.parse_args() with open(args.metrics_path) as f: metrics = json.load(f) if metrics[‘accuracy’] < args.threshold_accuracy: print(f”Model accuracy {metrics[‘accuracy’]} below threshold”) raise SystemExit(1) # fail pipeline print(f”Model passed: accuracy {metrics[‘accuracy’]}”) if __name__ == ‘__main__’: main()
The pipeline orchestrates training, evaluation, registration, and deployment. It runs on push to main or on a schedule. If the evaluation passes, the model is uploaded to the registry (S3 in this example), and a Docker image containing the serving code is built and deployed. This setup demonstrates CI/CD for machine learning models, ensuring automated training, evaluation, and deployment on every approved change.
# .github/workflows/ml-pipeline.yml name: MLOps Pipeline on: push: branches: [main] paths: [‘src/**’, ‘data/**’] schedule: – cron: ‘0 2 * * 0’ # weekly retrain env: RUN_ID: ${{ github.sha }} jobs: train: runs-on: ubuntu-latest steps: – uses: actions/checkout@v4 – uses: actions/setup-python@v5 with: { python-version: ‘3.11’, cache: ‘pip’ } – run: pip install -r requirements.txt – run: python src/train.py – run: python src/evaluate.py –threshold-accuracy 0.75 – uses: actions/upload-artifact@v4 with: name: model-${{ env.RUN_ID }} path: outputs/ deploy: needs: train runs-on: ubuntu-latest steps: – uses: actions/checkout@v4 – uses: actions/download-artifact@v4 with: { name: model-${{ env.RUN_ID }} } – name: Push to S3 registry run: | aws s3 cp outputs/model \ s3://${{ secrets.MODEL_BUCKET }}/models/${{ env.RUN_ID }}/ \ –recursive – name: Build and push serving image run: | docker build -t ${{ secrets.REGISTRY }}/ml:${{ env.RUN_ID }} serving/ docker push ${{ secrets.REGISTRY }}/ml:${{ env.RUN_ID }} – name: Deploy to staging run: | kubectl set image deployment/ml-api \ ml=${{ secrets.REGISTRY }}/ml:${{ env.RUN_ID }} -n staging
CASE STUDY · Uber
Michelangelo: MLOps platform serving thousands of models in production
Uber’s Michelangelo platform is one of the most well-documented examples of MLOps at scale. In published engineering blog posts and conference talks, Uber describes managing thousands of machine learning models across use cases ranging from demand forecasting to fraud detection.
Michelangelo provides end-to-end automation: data pipelines that version and validate datasets, training pipelines that run on Spark or Kubernetes with automatic hyperparameter tuning, a model registry that stores artifacts with full lineage metadata, and deployment infrastructure that supports both online and batch inference with canary analysis and automatic rollback.
Key architectural decisions include treating models as first-class versioned artifacts, maintaining strict separation between training and serving code to avoid dependency conflicts, and investing heavily in monitoring and alerting for model performance degradation and data drift. Uber credits Michelangelo with enabling product teams to deploy models independently without deep ML infrastructure expertise, reducing time-to-production from months to weeks.
The serving layer loads the registered model and exposes a REST API for predictions. It should handle input validation and error handling and expose health endpoints for orchestration systems.
# serving/app.py import os from fastapi import FastAPI, HTTPException from pydantic import BaseModel app = FastAPI() MODEL_PATH = os.getenv(‘MODEL_PATH’, ‘/model/model.joblib’) model = None @app.on_event(‘startup’) def load_model(): global model import joblib model = joblib.load(MODEL_PATH) class PredictRequest(BaseModel): feature_a: float feature_b: float @app.post(‘/predict’) def predict(req: PredictRequest): if model is None: raise HTTPException(500, ‘Model not loaded’) import numpy as np x = np.array([[req.feature_a, req.feature_b]]) pred = model.predict(x) return {‘prediction’: float(pred[0])} @app.get(‘/health’) def health(): return {‘status’: ‘ok’, ‘model_loaded’: model is not None}
Production monitoring for ML systems requires tracking model-specific metrics and implementing model monitoring and drift detection in production environments. Implement logging for predictions and ground truth labels (when available), compute accuracy and drift metrics on a rolling window, and alert when thresholds are breached.
The business case for MLOps implementation is the same as the case for DevOps: automation, reproducibility, and velocity at scale.
Every model in production is traceable to the exact code commit and data version that produced it. When an incident occurs or an audit is conducted, you can answer: which model was running, when was it deployed, what data was it trained on, and what metrics did it achieve? This traceability is essential for regulated industries and for debugging production issues.
Read More: AIOps vs Traditional Monitoring: What Actually Changes and When It’s Worth It
Automated evaluation ensures that only models meeting minimum quality standards reach production. This prevents accidental deployments of undertrained models, models with data quality issues, or models that regress on key metrics. The cost of a bad model deployment—incorrect predictions, customer complaints, and revenue loss—is high. Evaluation gates reduce that risk.
Automating training, evaluation, and deployment means that retraining is a scheduled job or a triggered pipeline, not a manual process requiring multiple teams and days of coordination. This enables rapid iteration: test a hypothesis, retrain, evaluate, deploy to staging, and measure impact within hours or days rather than weeks or months.
One well-designed MLOps pipeline can support dozens or hundreds of models across multiple teams. Teams do not need deep ML infrastructure expertise to deploy models; they consume the platform. This allows the organization to scale its ML footprint without proportionally scaling the ML infrastructure team.
PREREQUISITES FOR SUCCESS
✓Version control for code and configuration—every change is tracked. ✓Data versioning or clear dataset snapshots—training runs are reproducible. ✓ CI/CD infrastructure—pipelines can run training and deploy automatically. ✓Model registry—artifacts and metadata are stored in a queryable system. ✓Monitoring and alerting—production models are continuously observed.
Metaflow: Open-source MLOps framework for data scientists
Netflix developed Metaflow, an open-source Python framework for managing machine learning workflows, to address the gap between data science experimentation and production deployment. In published blog posts and conference talks, Netflix describes Metaflow as providing automatic versioning of code and data for every training run, seamless transition from local development to cloud-scale training on AWS Batch or Kubernetes, built-in experiment tracking and artifact storage, and straightforward deployment patterns that allow data scientists to deploy models to production without requiring deep DevOps expertise.
Key design principles include keeping the API simple and Pythonic so data scientists do not need to learn a new paradigm, providing sensible defaults for infrastructure choices while allowing customization when needed, and treating failure recovery and reruns as first-class concerns. Netflix credits Metaflow with reducing the time from model development to production deployment from weeks to days and enabling data science teams to operate more independently.
MLOps is not plug-and-play. The following considerations are non-negotiable for a production-grade implementation.
For small datasets that fit in the repository, versioning is straightforward. For large datasets in object storage or databases, you need a versioning strategy: DVC for local and cloud storage, Delta Lake for data lakes, or explicit snapshot management with manifest files. Without data versioning, training runs are not reproducible.
A model registry is only useful if it is kept up to date. Every model deployed to production must be registered with metadata. Every rollback must be documented. If the registry falls out of sync with reality, it becomes a liability rather than an asset. Discipline and automation are required.
Model performance monitoring requires ground truth labels, which may arrive with delay (e.g., for credit risk models, true defaults occur months after prediction). Drift detection requires defining reference distributions and alert thresholds. This is not a one-time setup; it requires ongoing tuning and maintenance.
Pipeline secrets (cloud credentials, registry access tokens) must be managed securely. Use CI/CD secrets management, not hardcoded credentials. Restrict who can approve production deployments. Treat the model registry and production serving infrastructure with the same security rigor as any production system.
Training CI runners can be expensive if runs are long or require GPUs. Use path filters and schedules to avoid unnecessary training runs. For large-scale training, offload to dedicated compute (AWS Batch, Kubernetes GPU nodes) triggered by the pipeline rather than running in the CI runner itself.
An end-to-end MLOps pipeline treats machine learning models as software artifacts: versioned, tested, deployed, and monitored with the same rigor as any production service. The six stages—data versioning, reproducible training, evaluation gates, model registry, controlled deployment, and production monitoring—form a complete lifecycle that enables teams to move from notebook experiments to production systems that deliver value over time.
This tutorial provided one concrete implementation using Python, GitHub Actions, S3, and FastAPI. The specific tools are less important than the structure: explicit inputs and outputs, automated evaluation gates, versioned artifacts with metadata, and continuous monitoring. Adapt the pattern to your stack—GitLab CI instead of GitHub Actions, SageMaker instead of S3 and FastAPI, and MLflow instead of a custom registry—but retain the discipline.
The business case is straightforward: reproducibility for debugging and audits, quality gates to prevent bad deployments, automation for velocity and scale, and monitoring to catch degradation before it becomes a crisis. The investment is in building and maintaining the pipeline infrastructure and in the discipline to use it consistently across all models and teams.
The return is a production ML system that scales with the organization and that treats models as the valuable, long-lived assets they are. Companies offering AI development services increasingly position MLOps not as optional infrastructure, but as a foundational layer for any serious AI initiative.

